
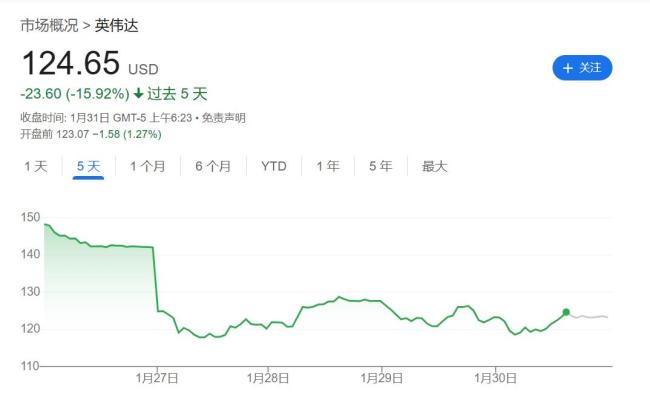
2025年1月中旬,英伟达CEO黄仁勋访问中国,从北京到深圳,再到台中和上海,引起广泛关注。然而,在距离英伟达上海办公室仅200公里的杭州,一家名为深度求索(DeepSeek)的中国公司正在悄然酝酿一场足以撼动AI产业格局的风暴。1月20日,DeepSeek开源了推理模型DeepSeek-R1,这一事件迅速引起了全球关注,导致英伟达市值一周内蒸发了5520亿美元。


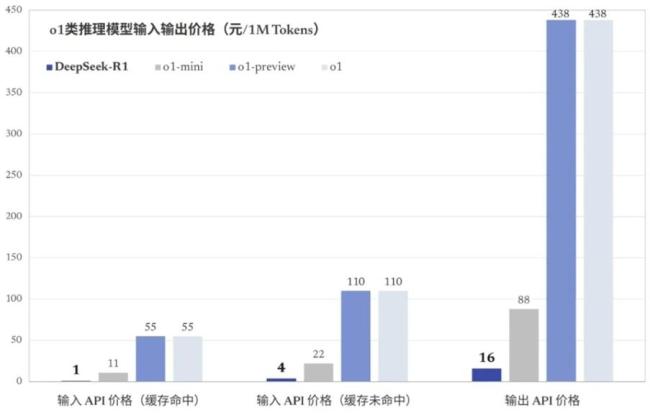
DeepSeek的崛起主要得益于其在性能、价格和开源方面的三重冲击。1月24日发布的聊天机器人竞技场榜单上,DeepSeek-R1综合排名第三,与OpenAI的ChatGPT并列,并在高难度提示词、代码和数学等领域位列第一。DeepSeek-R1的价格低得惊人,仅为竞争对手的2%~3%,且完全免费提供移动应用和网页端服务。此外,DeepSeek-R1完全开源,任何人都可以自由使用、修改、分发和商业化该模型。
著名投资公司A16z的创始人马克·安德森认为,Deepseek-R1是令人惊叹的突破之一,而且还是开源的,堪称给世界的一份礼物。Scale AI创始人亚历山大·王表示,DeepSeek的发布可能会改变中美在AI竞赛中的局势。
华尔街对此感到焦虑,投资者开始质疑巨头们在算力上的投入是否值得。投行Jeffreies股票分析师Edison Lee团队指出,美国AI企业的管理层可能面临更大的压力,需要回答进一步提高AI资本支出是否合理的问题。摩根大通分析师Joshua Meyers则认为,DeepSeek的低成本并不意味着扩张的终结,也不意味着不再需要更多的算力。

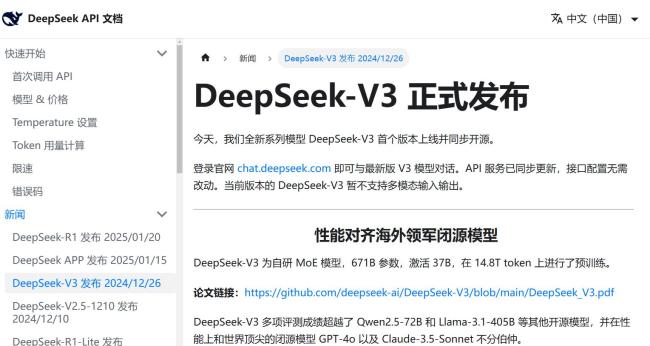
DeepSeek的成功部分归功于数据蒸馏技术,但这一技术在行业内存在争议。南洋理工大学研究人员王汉卿表示,被训练的模型无法真正超越“教师模型”。不过,DeepSeek-V3的创新不仅于此,其精简有效的架构和自主提出的MLA机制也降低了缓存使用。
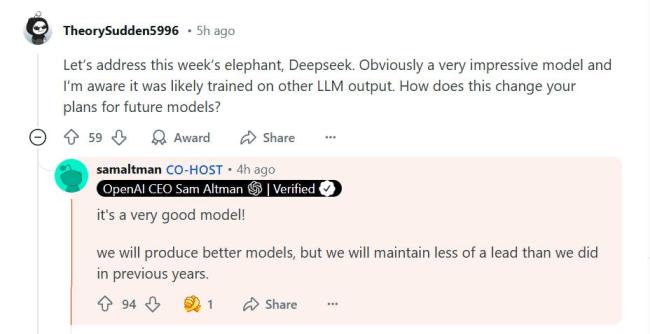
DeepSeek选择了一条与OpenAI截然不同的技术路线,完全摒弃了传统的监督微调环节,依赖强化学习进行训练。DeepSeek创始人梁文锋强调原创的重要性,他认为只有通过原创才能摆脱追随者的地位。OpenAI首席执行官山姆·阿尔特曼承认DeepSeek是一个非常好的模型,并表示将推出更好的模型。

科技巨头如微软、AWS和英伟达纷纷接入DeepSeek-R1模型服务。微软将其添加到Azure AI Foundry,AWS也在其平台上部署了DeepSeek-R1。英伟达宣布DeepSeek-R1作为NVIDIA NIM微服务预览版发布。AMD也宣布DeepSeek-V3模型已集成至AMD Instinct GPU上。
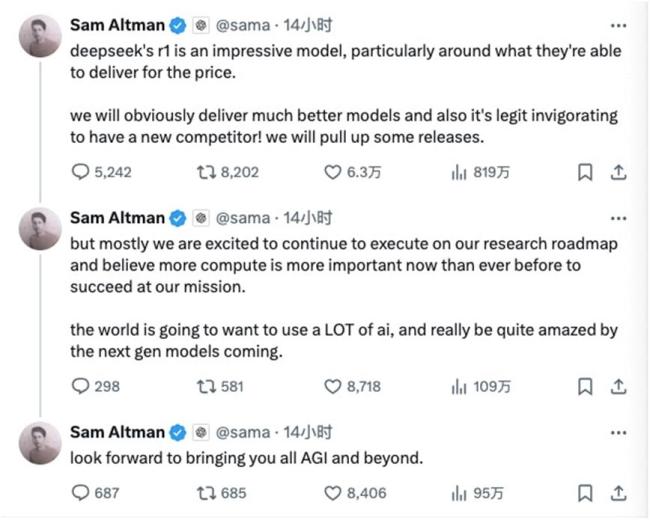
DeepSeek的出现引发了对AI未来发展的讨论。吴恩达提醒,扩大规模并非实现AI进步的唯一途径,算法创新同样重要。随着训练成本降低和技术成熟,大语言模型将愈发成为一种普通产品。Hugging Face联合创始人托马斯・沃尔夫认为,许多这类模型将会免费且可自由获取。巧合的是,同日,OpenAI推出了全新推理模型o3-mini,并首次向免费用户开放。Sam Altman罕见承认OpenAI过去在开源方面站在“历史错误的一边”,并表示需要想出一个不同的开源策略。
文章来源于网络。发布者:火星财经,转载请注明出处:https://www.sengcheng.com/article/17054.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 