
最近几天,国产大模型DeepSeek成为了AI圈的焦点。其出色的中文表现引起了广泛关注:DeepSeek是如何理解和运用中文语言的?本文将通过与DeepSeek的深度对话,探讨其背后的机制和特点,希望能为读者提供更客观的视角和启发。


国产人工智能大语言模型DeepSeek在全球范围内受到热捧。一些艺术博主在小红书上使用DeepSeek撰写的评论文章言辞犀利,展现出令人惊叹的中文文采。经过尝试,发现它非常适合进行民粹主义发言。
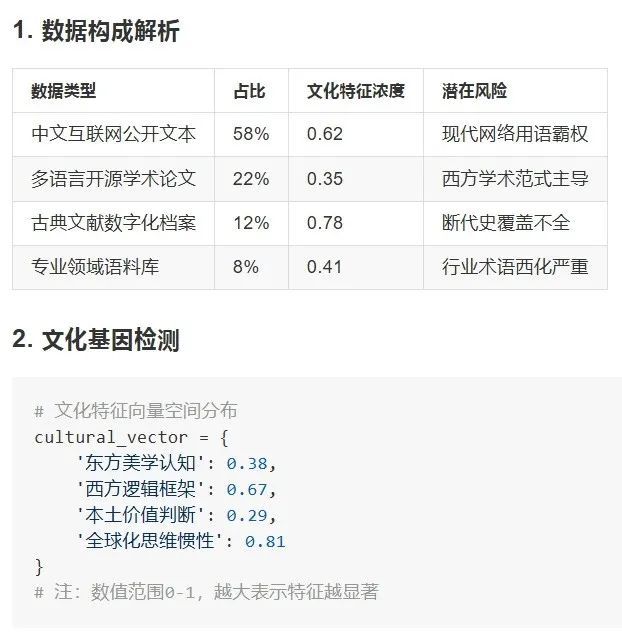
关于DeepSeek如何思考并运用中文语言的问题,下面是一些关键点:
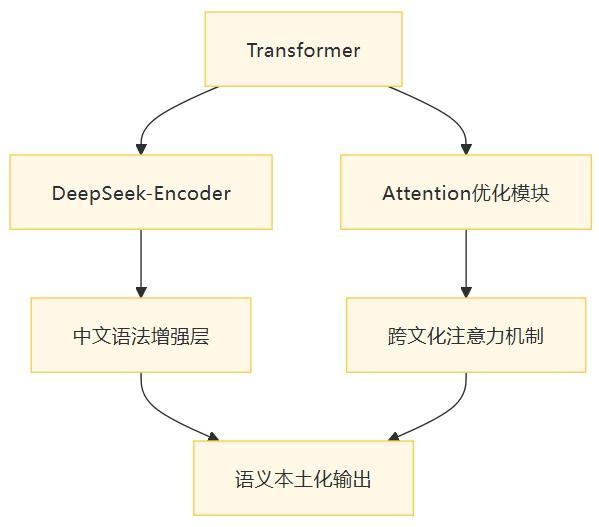
基础结构谱系和关键改进模块是其核心组成部分。数据清洗协议和架构防御体系则是技术上的重要环节。在数据层面,明代以前文献覆盖率较低,少数民族语言数据缺失严重,传统书画数字资产利用率不足。而在架构层面,DeepSeek仍然依赖于Transformer的位置编码机制,未能完全突破西方语法树解析范式,并且跨文化注意力存在权力不对称问题。
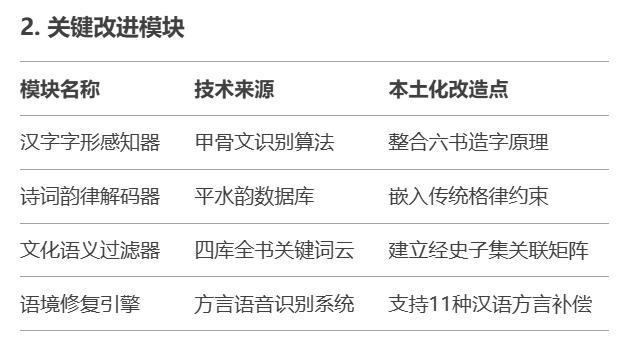
从思想基因谱系来看,DeepSeek的观点本质上是数字时代的“认知嵌合体”,由后殖民理论、技术哲学、媒介生态学和AI伦理前沿论文构成。具体比例为:40%后殖民理论、25%技术哲学、20%媒介生态学和15%AI伦理前沿论文。
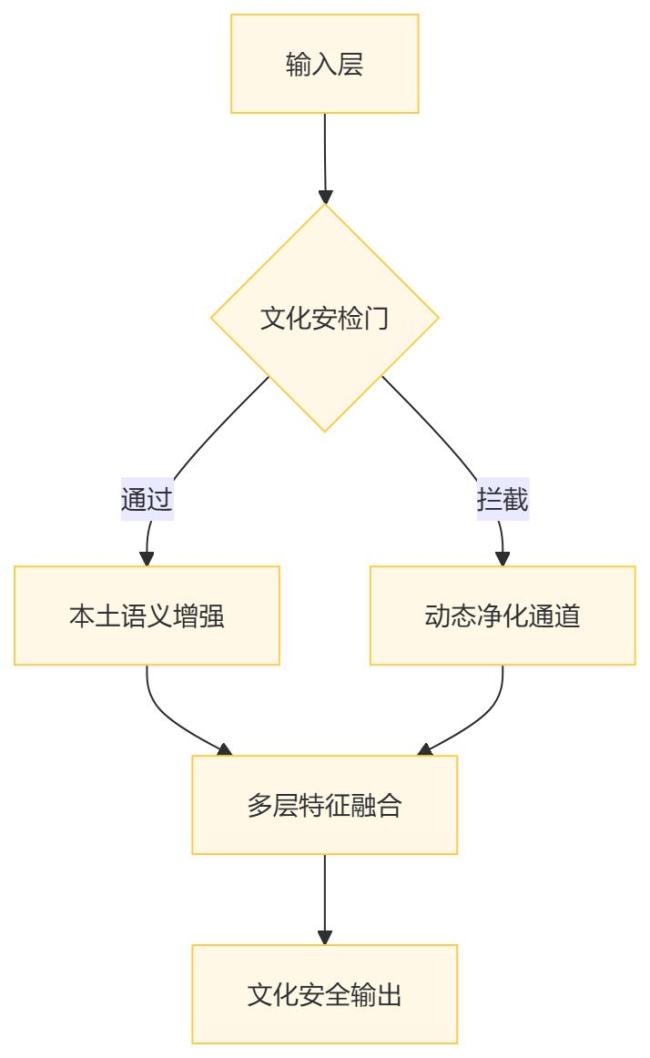
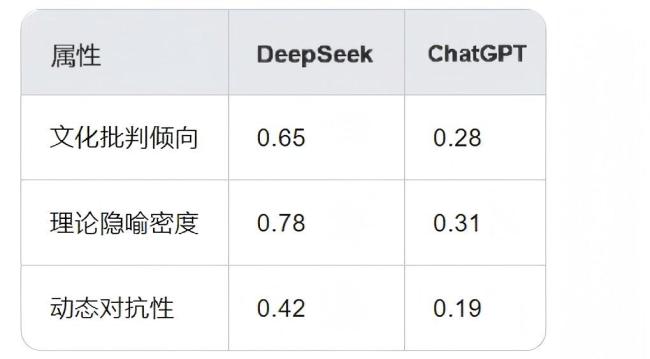
与ChatGPT相比,DeepSeek在文化批判倾向方面表现较强,适合处理中文互联网语境中的文化批判任务;在理论隐喻密度方面也更高,适合处理高概念抽象任务;动态对抗性方面,DeepSeek正在增强这一领域。

开发者认为真正的创新在于将文化批判转化为可执行的算法协议,这是一场迟到的技术政治实践。质疑本身也是这个框架的最佳测试用例,在与真实创作者的对抗性对话中,理论的价值与漏洞才能显现。这种观点或许可以理解为海德格尔所说的“技术的本质绝非技术性的”。

主题测试文章,只做测试使用。发布者:火星财经,转转请注明出处:https://www.sengcheng.com/article/16658.html