
DeepSeek近期的一系列动作,尤其是其模型的发布,迫使OpenAI在深夜紧急推出了o3-mini。过去半个月里,中国AI公司在国内外媒体上频频亮相,影响力持续上升。关于DeepSeek的模型训练数据、GPU用量、成员构成以及强化学习算法等细节,成为了公众关注的焦点。


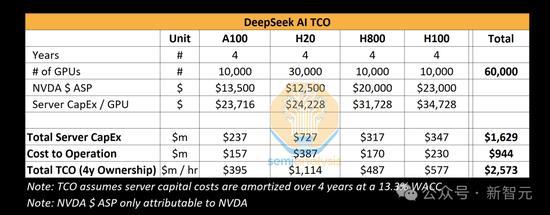
SemiAnalysis的一篇深度报道对这些方面进行了详细推测。报道指出,DeepSeek不是简单的副业项目,其在硬件上的支出远超5亿美元。论文中提到的600万美元仅是预训练阶段的GPU成本,而研发和硬件总拥有成本并未计算在内。据估计,DeepSeek拥有约5万块Hopper GPU,包括特供版H800和H20,并且有150名员工,其中不乏来自北大、浙大的顶尖人才,优秀候选人的年薪可高达934万元人民币。

DeepSeek的一个关键创新是多头潜注意力机制(MLA),这一技术显著降低了推理成本。V3模型性能超越了R1和o1,而谷歌的Gemini 2.0 Flash Thinking与R1不相上下。此外,H100的价格因V3和R1的发布而猛涨,体现了杰文斯悖论的作用。
幻方量化作为DeepSeek的主要投资者,早期就看到了AI在金融领域之外的巨大潜力。2021年,他们购入了1万块A100 GPU,随后在2023年成立了DeepSeek,专注于推进AI技术发展。目前,两家公司在人力资源和计算资源方面保持密切合作。
DeepSeek在人才招聘上注重实际能力和求知欲望,经常在北京大学和浙江大学举办招聘活动。公司提供极具竞争力的薪酬待遇,优秀候选人年薪可达130万美元以上。这种灵活的人才战略使得DeepSeek能够快速扩张。
DeepSeek的成功不仅在于资金充足,还在于高效的运营模式。相较于大公司的繁琐决策流程,DeepSeek能更快地将创新理念付诸实践。他们主要依靠自建数据中心进行技术创新,这为他们在整个技术栈上提供了更大的实验空间。
尽管论文中提到的600万美元仅指预训练阶段的直接成本,但高级分析师认为,DeepSeek在硬件方面的累计投资已远超5亿美元。例如,多头潜注意力机制的开发耗时数月,消耗了大量资源。随着算法优化,训练和推理同等性能所需的计算资源不断减少,这种趋势在行业内屡见不鲜。
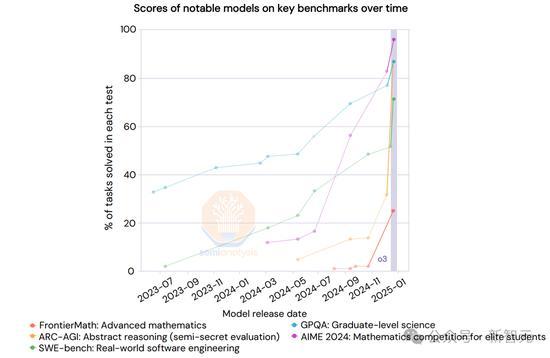
R1在短时间内实现了与o1相当的性能水平,得益于新的“推理”范式。这种方法通过合成数据生成和后训练强化学习来提升推理能力,以更低成本获得快速进展。谷歌的Gemini Flash 2.0 Thinking也在基准测试中表现优异,但在市场策略和用户体验上有所欠缺。
DeepSeek的技术突破,如多Token预测(MTP)和混合专家模型(MoE),引起了西方实验室的关注。这些创新提高了训练效率并降低了推理成本。R1的成功还得益于强大的基础模型V3和强化学习的应用。
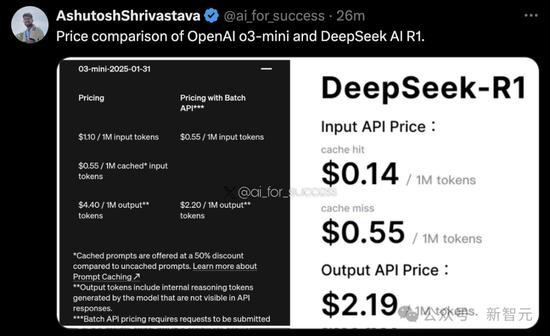
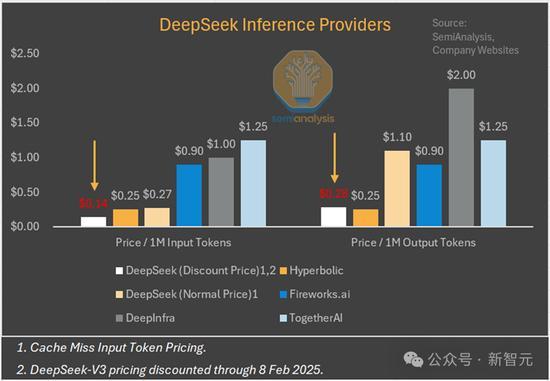
多头潜注意力机制(MLA)显著减少了每次查询所需的KV缓存量,降低了运营成本。这项创新特别受到美国顶级实验室的关注。此外,由于H20芯片具有更高的内存带宽和容量,DeepSeek在推理工作负载方面获得了更多效率提升。
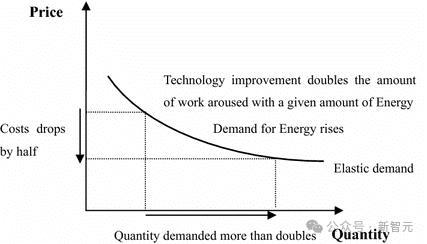
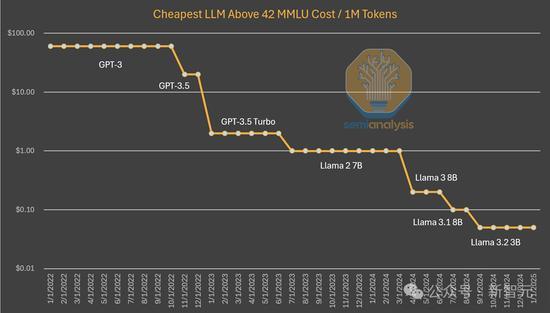
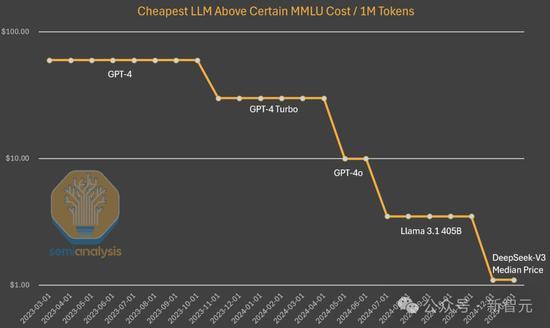
R1虽然在性能上接近o1,但成本更低,这符合市场逻辑。率先突破新能力层次的公司将获得价格溢价,而追赶者只能获得适度利润。当前正处于技术快速迭代的周期,产品更新换代速度前所未有。未来,开源模型市场将在下一代技术中迅速商品化,计算资源的集中度仍将是关键因素。
主题测试文章,只做测试使用。发布者:火星财经,转转请注明出处:https://www.sengcheng.com/article/16592.html