
中国AI模型DeepSeek引发了全球讨论热潮,持续近半个月后,美国OpenAI公司推出了新的AI推理模型o3-mini作为回应。北京时间2月1日凌晨,OpenAI CEO奥尔特曼在ChatGPT和API服务中发布了o3-mini。该模型的性能响应速度比之前的o1-mini提升了24%,答案准确性也有所提高。


目前,ChatGPT免费用户可以体验一个有限速率的o3-mini版本,而Plus用户可选择更高智能版本o3-mini-high;每月支付200美元的Pro用户则可无限使用这两个版本。在API层面,o3-mini的价格比o1-mini便宜63%,但仍比GPT-4o mini贵7倍左右。

OpenAI表示,o3-mini的发布标志着高效能智能技术道路上的重要里程碑。通过优化科学、技术和工程领域的推理能力,同时保持较低的成本,高质量AI技术变得更加平易近人。
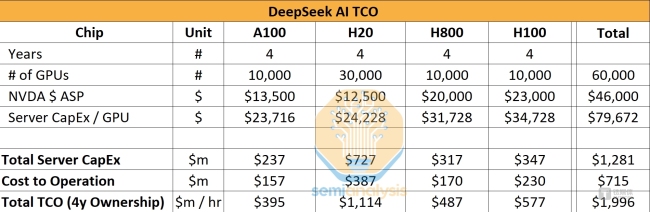
过去一周内,DeepSeek R1和V3两款开源AI模型颠覆了世界对于“尺度定律”的看法。其优异表现以及低成本令OpenAI内部震动,并引发华尔街对算力成本投入的质疑。据SemiAnalysis报道,DeepSeek拥有6万张英伟达GPU卡,总体拥有成本超过140亿元人民币。这使得英伟达股价一夜暴跌17%,损失近6000亿美元市值。
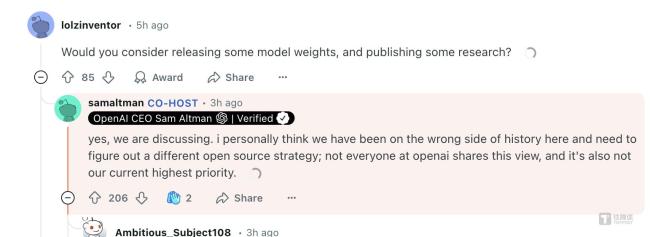
最新消息显示,OpenAI正在进行新一轮400亿美元的融资,软银将领投,公司估值高达3000亿美元。与此同时,奥特曼承认OpenAI在开源方面曾站在历史错误的一边,正在考虑不同的开源策略。
回顾过去四年,DeepSeek创始人梁文锋带领团队深入研发大模型。由于背后有幻方量化支持,DeepSeek不缺资金且不追求商业化。人才方面,DeepSeek提供高额年薪吸引顶尖人才,注重能力和求知欲。基于这种模式,DeepSeek以较低成本实现了高性能的AI模型训练。
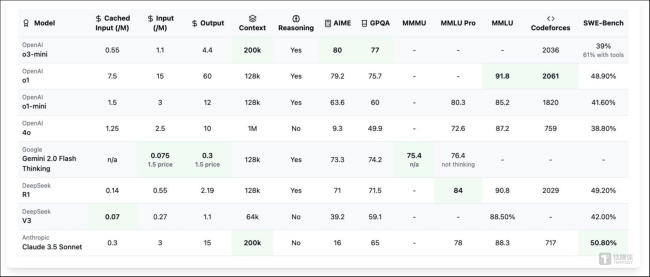
清华大学计算机系教授翟季冬认为,DeepSeek在算法和系统软件层次做了许多创新,对中国未来发展AI产业至关重要。如今,o3 mini和DeepSeek R1都使用大量监督微调、强化学习等技术,展示了稀疏化MoE架构的重要性。
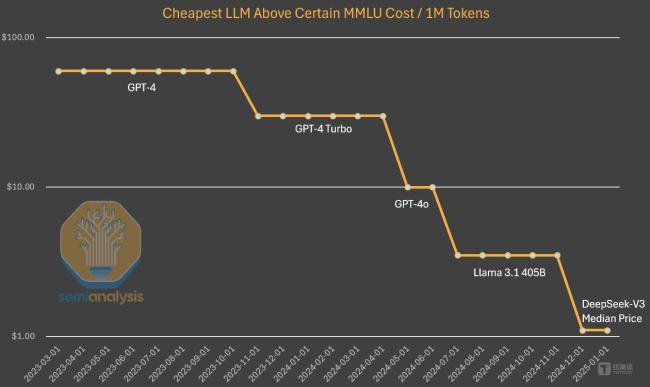
整体来看,算法的进步使得模型训练成本大幅降低,同时提高了模型的能力。Anthropic首席执行官Dario Amodei认为,算法的进步可以带来10倍的改进,GPT-3质量的推理定价已下降1200倍。

OpenAI发布的o3-mini模型在价格和性能上具有竞争力,多项技术能力超越了DeepSeek R1。奥尔特曼首次正面承认OpenAI的闭源是一个错误,并计划将某些模型进行开源。此外,o3-mini模型在科学、数学和编码方面表现出色,测试人员更喜欢其回答。
然而,DeepSeek正面临美国政企各方面的调查压力。微软和OpenAI开始调查DeepSeek是否采用其数据,美国总统特朗普警告称需要限制对华AI半导体出口。Dario Amodei认为,DeepSeek的突破迫使美国重新评估技术封锁政策的有效性。
中欧国际工商学院教授谭寅亮表示,DeepSeek的成功依赖于高效的算力调度和模型优化能力,而非单纯堆积硬件资源。中国在应用层面和用户体验上有强大创新能力,但在底层技术上仍需追赶美国。
主题测试文章,只做测试使用。发布者:火星财经,转转请注明出处:https://www.sengcheng.com/article/16586.html