
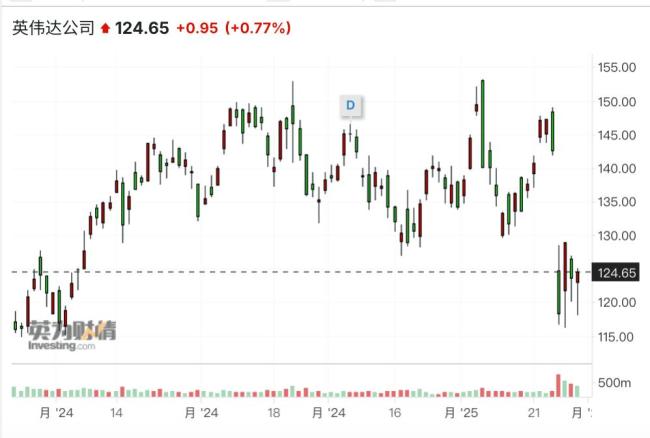
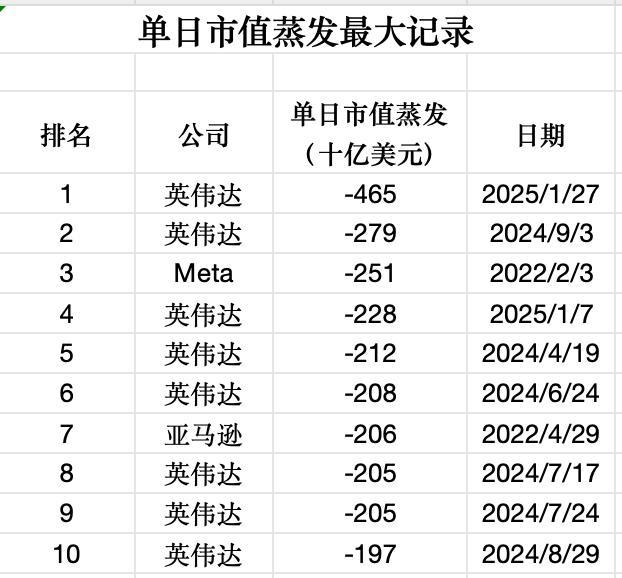
过去一周,DeepSeek R1、字节跳动的豆包1.5 Pro以及月之暗面的Kimi k1.5模型相继推出,引发了全球投资者的高度关注。DeepSeek的表现优异且算力成本仅为OpenAI的近1/20,导致英伟达股价一夜暴跌17%。

DeepSeek确实引发了华尔街投资经理的焦虑,尤其是那些重仓科技股的大盘股基金经理。尽管DeepSeek只是缩小了与OpenAI o1的距离,并未超越,而且OpenAI已更新到o3,但DeepSeek引发了对大模型价格战和算力需求下降的担忧。
经历一夜暴跌后,英伟达等科技巨头股价在后续几天有所反弹,华尔街开始对“中国AI冲击”进行更理性的分析。DeepSeek的问世意味着更多新进入者,算力需求将有增无减,不过未来的热点可能会从基础设施转向应用端,更多AI公司将会受益。
高盛首席全球股票策略师Peter Oppenheimer表示,由DeepSeek大模型引发的股市修正标志着自去年秋季以来,“Magnificent 7”首次下跌超过3.5%。他认为这是一次修正而不是长期熊市的开始。大多数熊市通常由预期利润下滑引发,这种预期通常源于对衰退的担忧。高盛预计未来12个月衰退的概率为15%,利率将会小幅下调,通胀将逐步缓解,而AI领域更低价的新进者可能会增强这一趋势的信心。
近几日,华尔街基金经理的心情如同英伟达股价一样坐上过山车。1月28日,英伟达暴跌17%,从142美元跌至118美元;29日反弹7%至128美元附近;30日再度大跌4%至122美元附近;31日收于124美元。一位中盘股基金经理表示,不仅英伟达暴跌,连电力股也受到了影响。另一位软件分析师指出,尽管DeepSeek并未超越OpenAI o1,但它引发了对大模型价格战和算力需求下降的担忧。
截至1月26日,DeepSeek在美国区苹果App Store免费榜升至第六位,超越了Google Gemini和Microsoft Copilot等美国科技公司的生成式AI产品。DeepSeek发布的推理大模型DeepSeek-R1以开源形式问世,性能比肩OpenAl的闭源旗舰模型o1,但训练成本仅为后者的1/20。这一突破不仅让硅谷陷入焦虑,还暴露了AI领域长期依赖硬件堆砌与封闭生态的脆弱性。DeepSeek主要基于Meta的开源大模型Llama系列,特别是Llama 2,并结合了自研优化和大规模训练技术,提升了模型性能。
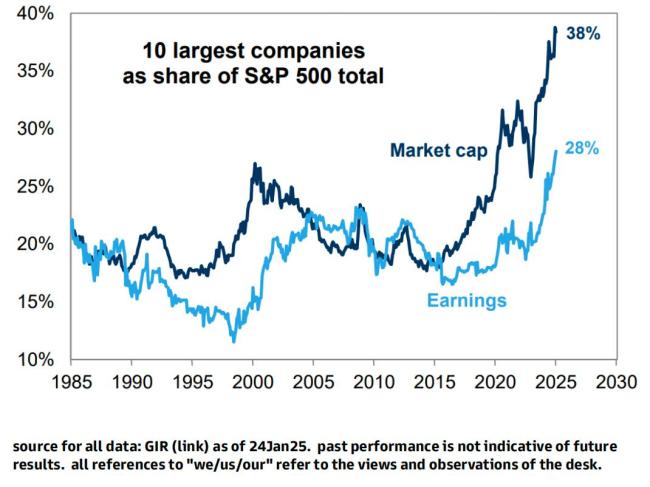
高盛最新报告指出,市场既奖励了在AI上大举投入的公司(如亚马逊、微软、谷歌、OpenAI等),也奖励了提供工具和基础设施的公司(如英伟达、博通、Vertiv,以及广泛的半导体行业)。然而,DeepSeek模型的低成本特点正在动摇投资者对整个AI生态系统的信心,质疑未来是否仍需要相同类型的巨额支出和投资。
早在去年三季度,高盛就发布多份报告,预警AI开支太大的风险。数据显示,谷歌、Meta、亚马逊、微软、苹果和甲骨文的资本支出总额一直在大幅增长,2023年支出高达约1600亿美元,2024年的资本支出预计将增加到2000亿美元。这种增长消耗了这些企业的大部分增量自由现金流。
随着纳斯达克100指数年内涨幅被完全抹去,投资者面临的问题是抄底还是观望。对于观望者而言,DeepSeek带来的冲击可能导致重新审视AI投资的必要性。同时,随着进入门槛降低,AI领域可能出现互联网巨头与初创企业之间的竞争。高盛对冲基金研究主管Tony Pasquariello表示,AI不会重演互联网泡沫的崩盘,但可能会有相似的节奏——即大量资本支出先行,真正的大规模回报可能还需4~5年才能兑现。
对于倾向于抄底的一方,多位投资经理和分析师认为,在2025年的AI智能体时代,应用场景加速普及,高端显卡仍是市场的香饽饽,英伟达仍将是核心主导。某资深投资人士表示,DeepSeek引发的抛售有些过度,最终各界需要的算力只会更多。
英伟达被称为“AI淘金潮”下那个“卖铲子的人”,但未来的热点可能会继续向中下游切换。高盛科技分析师Eric Sheridan强调,AI主题的下一阶段演进可能会从基础设施层转向应用层,如AI智能体、企业应用场景、消费者实用性提升和计算习惯的改变。不同行业的格局将发生变化,例如,半导体因AI训练计算成本下降而面临股票抛售压力和估值受压;软件则受益于效率提升和成本下降,可能加速企业AI的采用。
在科技巨头中,谷歌和Meta相对处于特别有利的位置,因为它们在AI的应用层推进方面走得最远。富兰克林股票团队首席投资官柯蒂斯表示,在应用端将有更多使用案例出现,更多市值较低的企业将受惠,特别是在软件和互联网服务等行业。
不可否认的是,近两年来,中国AI企业的发展超出预期,DeepSeek的爆红增加了相关主题的吸引力。OpenAI原全球市场应用负责人Zack Kass认为,在未来AI竞赛中,中国不一定会落后,可以用更少的GPU构建模型。2025年,人们将开始认同“模型即商品”的理念,模型将越来越便宜和可触达。人们的关注点将从“谁的模型更强”转向如何更有效地采用和应用这些模型。
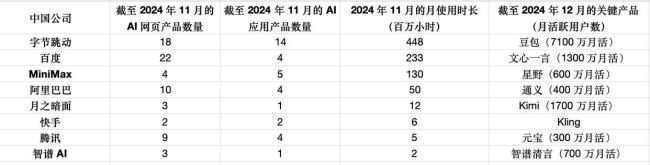
高盛认为,未来AI推理与后训练环节受到更多重视,推理计算资源需求低于预训练,将成为下阶段增长重点。依托高性能和低成本优势,中国AI企业具备全球竞争力。尤其是在To C应用方面,中国企业具备先发优势,核心盈利模式是广告、订阅等增量收入,实现AI应用可持续变现。例如腾讯的微信是一款“超级应用”,适合AI智能体的发展;字节跳动的豆包AI月活超7000万,已升级至1.5 Pro版本。
在云计算和数据中心领域,围绕芯片、算力限制的地缘政治不确定性依然存在,但训练、推理成本优化的进展也在提速。瑞银认为,AI软件及应用受益者包括金山办公、科大讯飞,它们将受益于AI在云端和前沿计算的加速渗透。数据中心受益者包括VNET,作为中国领先的数据中心运营商,将受益于AI数据中心需求增长。不过,中美在To B、To C端的AI应用有所不同,在中国,To C端的创业公司更为积极。
文章来源于网络。发布者:火星财经,转载请注明出处:https://www.sengcheng.com/article/16432.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 