
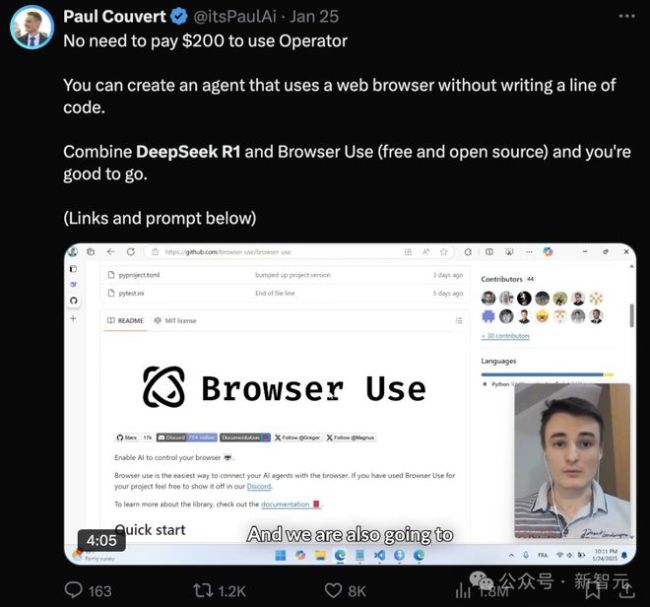
1月最后一天,DeepSeek的热度依旧高涨。在美国,无论是AI从业者还是普通民众,都感受到了来自中国AI技术的冲击。Anthropic CEO呼吁美国加强芯片管制,而OpenAI则寻求高达400亿美元的融资。网友们利用宽松的开源许可,制作了使用DeepSeek-R1替代OpenAI Operator的教程,无需200美元订阅,完全免费。


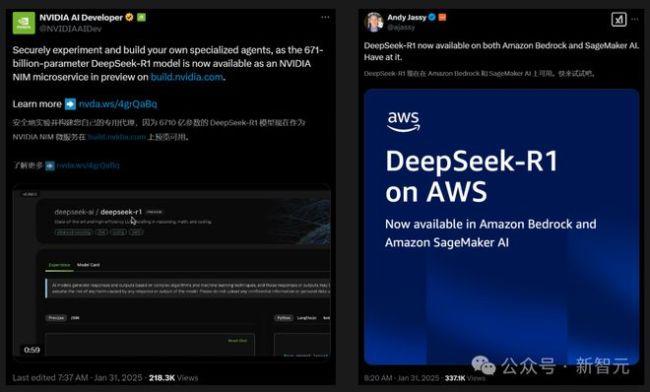
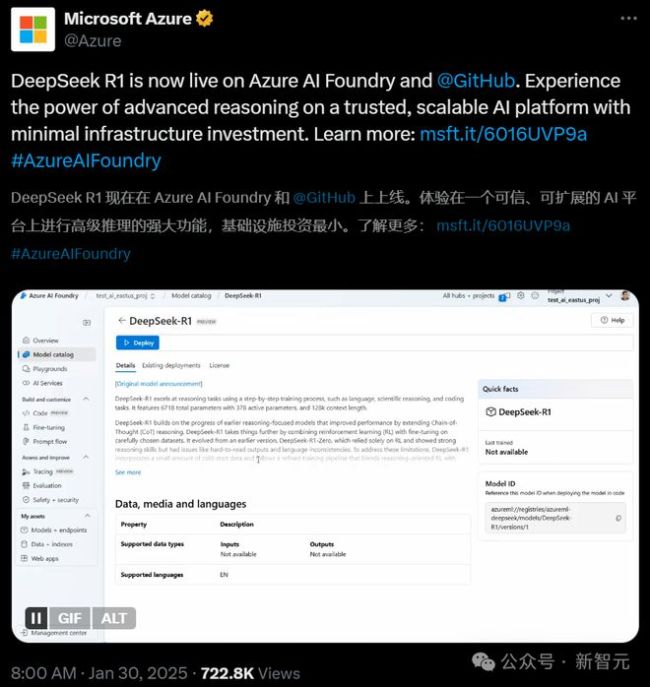
英伟达对DeepSeek赞赏有加,并宣布DeepSeek-R1正式登陆NVIDIA NIM。在单个NVIDIA HGX H200系统上,完整版DeepSeek-R1 671B的处理速度可达3,872 Token/秒。亚马逊也在Amazon Bedrock和SageMaker AI中上线了DeepSeek-R1模型。微软甚至提前将DeepSeek-R1部署在其云服务Azure上。
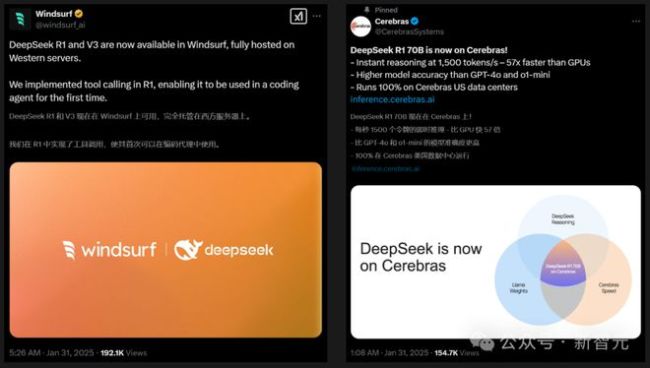
除了科技巨头,初创公司也抓住机会。Windsurf编辑器集成了DeepSeek-R1和V3模型,在编程智能体中实现了R1的工具调用。Cerebras声称其部署的70B模型不仅比GPU快57倍,还在准确率上超过了GPT-4o和o1-mini。
吴恩达认为,围绕DeepSeek的热议显示了几个重要趋势:中国在生成式AI领域正在赶上美国。尽管ChatGPT推出时美国明显领先,但随着Qwen、Kimi、InternVL和DeepSeek等模型的出现,中国的差距迅速缩小。特别是在视频生成等领域,中国已展现出一些领先优势。
DeepSeek-R1不仅开源了模型权重,还分享了一份详细的技术报告。相比之下,一些美国公司通过渲染AI危险来推动法规阻止开源发展。吴恩达指出,如果美国继续妨碍开源,这一环节可能由中国主导。
开放权重模型加速了LLM的Token价格下降,为开发者提供了更多选择。例如,OpenAI的输出价格为60美元/百万Token,而DeepSeek R1只需2.19美元。训练基础模型并提供API服务充满挑战,许多公司仍在寻找收回成本的方法。但在基础模型之上进行应用开发,则充满了商机。

关于通过扩大模型规模推动进步的观点很多,但DeepSeek团队因美国AI芯片禁令不得不在性能较低的H800 GPU上运行模型,这促使他们在优化方面进行了大量创新。最终,模型训练成本(不包括研究成本)不到600万美元。吴恩达认为,即使智能变得更便宜,人类仍会使用更多智能。

DeepSeek的成功引起了英特尔前CEO Pat Gelsinger的关注。他认为,针对DeepSeek的反应忽视了计算机发展历程中的三个教训:计算遵循“气体定律”,工程的本质是应对约束,以及开放终将胜利。DeepSeek展示了如何在资源受限的情况下以低得多的成本交付世界一流解决方案。此外,开放的研究和生态系统对于AI的未来发展至关重要。

主题测试文章,只做测试使用。发布者:火星财经,转转请注明出处:https://www.sengcheng.com/article/16410.html