
在人工智能领域,一场激烈的竞争正在上演。去年12月,国内大模型公司“深度求索”开发的DeepSeek应用推出了DeepSeek-V3,在全球AI领域引起了巨大反响。这款模型以极低的训练成本实现了与GPT-4等顶尖模型相媲美的性能,震惊了业界。不到一个月后,DeepSeek再次震动全球AI圈。
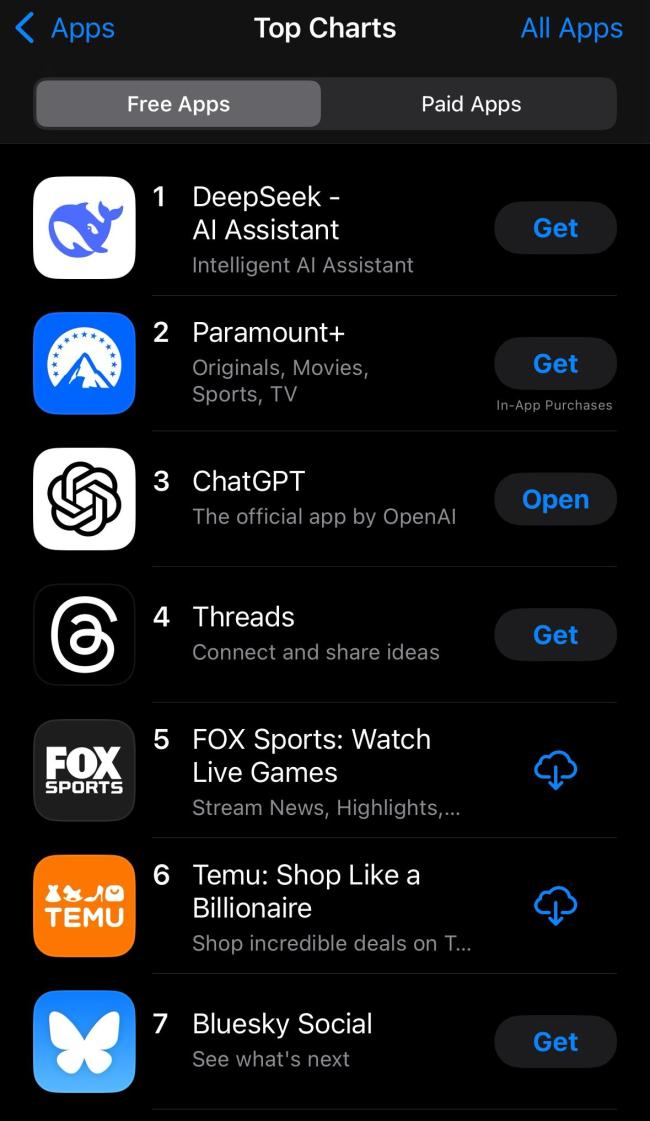

随着新模型DeepSeek-R1的推出,1月27日,Deepseek应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,并在美国区超越了ChatGPT。这一消息不仅在AI圈内引起了轩然大波,也让广大用户对这款新兴应用产生了浓厚兴趣。DeepSeek究竟好在哪?为什么能以较低的成本取得显著效果?开源是不是大模型未来的发展方向?
DeepSeek是一款由国内人工智能公司研发的大型语言模型,它拥有强大的自然语言处理能力,能够理解并回答用户的问题,就像和朋友聊天一样自然流畅。此外,DeepSeek还能帮助用户写代码、整理资料,甚至解决复杂的数学问题。它背后有复杂的算法和大量数据支持,能够从海量信息中挖掘出用户所需的内容。

说到类似的大模型,人们通常会想到OpenAI开发的ChatGPT。从2024年9月OpenAI发布o1-preview到现在,市场上已经出现了许多媲美甚至超越其性能的推理模型。然而,DeepSeek之所以能够脱颖而出,是因为它不仅率先实现了媲美OpenAI-o1模型的效果,还将推理模型的成本压缩到了极低。
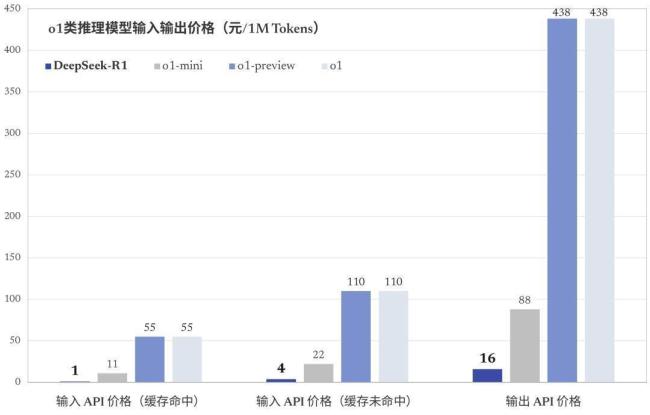
这次DeepSeek再次引起关注,是因为其新模型DeepSeek-R1延续了高性价比的优势,仅用十分之一的成本就达到了GPT-o1级别的表现。模型发布后,引发了海外AI圈众多科技大佬的讨论。例如,英伟达高级研究科学家Jim Fan在个人社交平台上表示,一家非美国公司正在延续OpenAI最初的使命——通过真正开放的前沿研究赋能全人类。游戏科学创始人、CEO冯骥也评价说,DeepSeek可能是个国运级别的科技成果。脸书母公司Meta已成立专门小组展开研究和学习。
北京邮电大学人工智能学院人机交互与认知工程实验室主任刘伟认为,DeepSeek的最大优势在于算法的改进和优化,节省了算力,减少了对大数据量的需求。以前如果说OpenAI是“大力出奇迹”,那么DeepSeek就是“小力也可以出奇迹”——小的算力用新的方法也能取得显著效果。南京大学人工智能学院教授俞扬指出,DeepSeek站在前人的基础上,在算法上进行了相应的优化,大幅降低了训练成本。
值得注意的是,DeepSeek采用了完全开源策略。曾经OpenAI创立的初衷是希望以最有可能造福全人类的方式推进数字智能发展,但后来限制了对模型的访问权限。相比之下,DeepSeek的开源策略不仅降低了用户的使用门槛,还促进了AI开发者社区的协作生态。通过开源,DeepSeek吸引了大量开发者和研究人员的关注,共同推动AI技术的发展。某大模型创业企业的CEO陈里奥认为,这种开放式的创新模式可以激发更多的创意和灵感,推动AI技术的不断进步。
当然,开源也面临着一些挑战和问题,如知识产权保护和维护开源社区秩序等。俞扬表示,开源只是一种商业模式,实际上开源的东西都是有版权的。因此,开源和闭源之争更多是关于哪种商业模式在特定场景和时代更有效。
有人把DeepSeek的成功归功于中国技术理想主义的故事,也有不少外国人将其比喻为神秘的东方力量。但从整个AI大模型产业来看,DeepSeek的成功或许代表了一种全新的发展方向。刘伟指出,现在大模型的发展正在发生变化,DeepSeek通过算法优化展示了即使算力不高,也能取得优异效果,开辟了新的方向。
文章来源于网络。发布者:火星财经,转载请注明出处:https://www.sengcheng.com/article/14644.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 