
这几天,中国人工智能初创公司DeepSeek在美区下载榜上超越了ChatGPT,还引发多个美国科技股股价暴跌。美国总统特朗普称DeepSeek的出现“给美国相关产业敲响了警钟”。

DeepSeek用较少的资金实现了与世界顶尖大模型如GPT-4相媲美的性能。OpenAI训练ChatGPT-4的成本高达7800万美元甚至可能达到1亿美元,而DeepSeek的大模型训练成本不到600万美元,仅为同性能模型的5%到10%。新模型训练方法大幅降低了大模型行业的入局门槛,使得大规模预训练不再是科技巨头的专利。此外,在模型推理层面,DeepSeek推出的DeepSeek-R1价格为2.2美元/百万词元,而同性能的OpenAI-o1价格为60美元/百万词元,前者仅为后者的三十分之一。这种低成本显著改善了大模型的应用成本,对科研、企业等智力密集型产业具有重大价值。因此,无论是从基础研究角度还是商业层面上看,DeepSeek对美国一些大模型公司的既有模式构成了冲击。
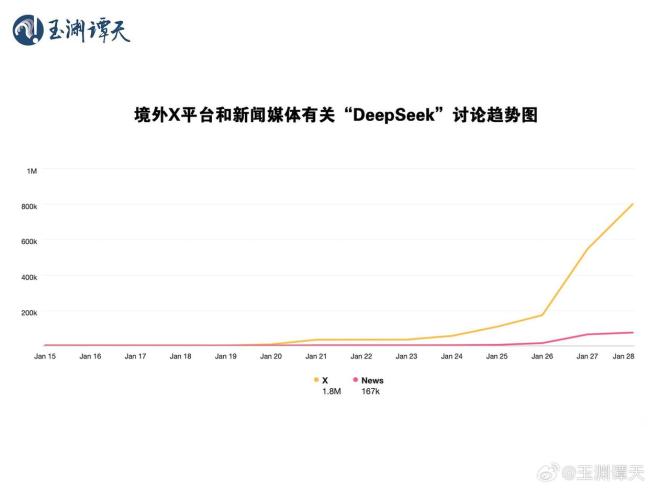
DeepSeek开发成本大幅降低的原因在于其应用了不同的模型训练模式,打破了美国堆砌算力的方式。在数据喂养这一重要环节上,OpenAI选择了“人海战术”,通过海量数据投喂提升能力。而DeepSeek则利用算法对数据进行总结和分类,经过选择性处理后再输送给大模型,从而优化了算力并降低了成本。目前来看,Meta耗费大量资金训练Llama,但效果不如成本极低的DeepSeek。这引发了Meta高层和技术人员的恐慌,他们担心自己的技术能力和创新性被质疑,从而失去工作。社交媒体上的讨论也显示,关于DeepSeek的帖子数量远高于新闻报道,且讨论时间早于新闻媒体五天,这主要是由从事科技工作的自媒体人和员工圈层传播所致。

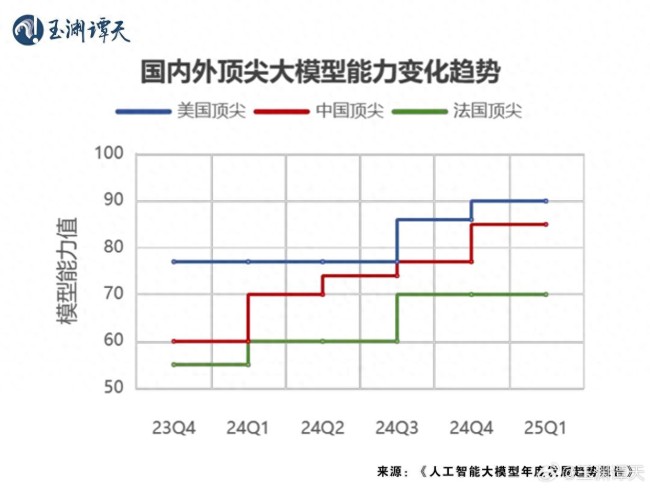
根据中国工业互联网研究院发布的《人工智能大模型年度发展趋势报告》,2024年国内大模型的能力进步显著。从2023年第四季度到2025年第一季度的测评显示,国内外大模型能力差距缩小了将近75%。这表明DeepSeek的出现是中国国内大模型整体发展的阶段性成果。尽管中国在AI领域的投资额仅为美国的十一分之一,但在未来仍有很大的发展空间。
如今,许多业内人士都喊出了“DeepSeek接班OpenAI”的口号。事实上,DeepSeek的出现并不是要取代其他公司,而是提出了更多样化的方案,打破了国际主流大模型的市场垄断,在大模型的发展道路上提供了不同于西方的中国解法,向世界展示了在大模型领域不仅仅只有拼算力一条路,再次证明了中国智慧的价值。
文章来源于网络。发布者:火星财经,转载请注明出处:https://www.sengcheng.com/article/14568.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 