
中国公司DeepSeek在华尔街周一评估“DeepSeek风暴”时,发布了其最新产品:名为Janus-Pro的多模态大模型。该模型在图像生成基准测试中超越了OpenAI的DALL-E 3,并且是开源的。

除夕凌晨钟声敲响前不久,DeepSeek工程师们在“抱抱脸”平台上传了Janus Pro 7B和1.5B两个模型,这是对去年10月发布的Janus模型的升级。这两个模型具有15亿和70亿参数量,可以在消费级电脑上本地运行。与之前的版本一样,Janus Pro采用MIT许可证,在商用方面没有限制。

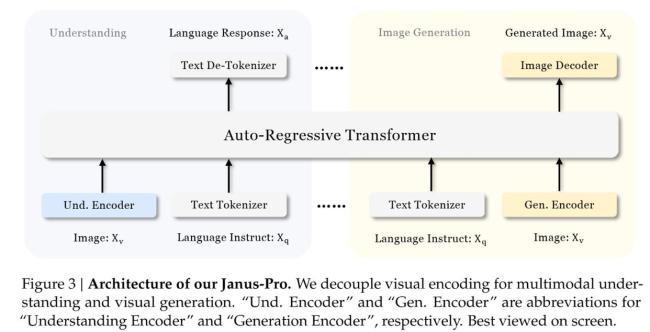
据DeepSeek介绍,Janus-Pro是一个新颖的自回归框架,统一了多模态理解和生成。通过将视觉编码分离为“理解”和“生成”两条路径,同时仍采用单一的Transformer架构进行处理,解决了以往方法的局限性。这种分离不仅缓解了视觉编码器在理解和生成中的角色冲突,还提升了框架的灵活性。
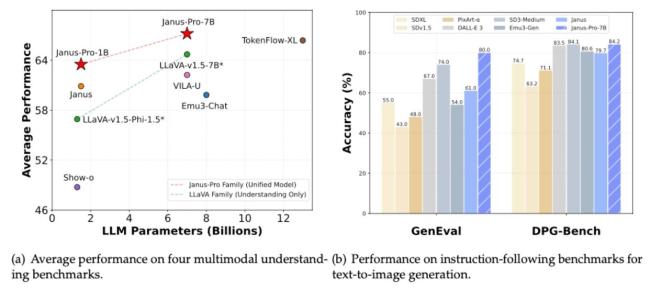
从报告给出的数据来看,在部分文生图基准测试中,Janus-Pro 70亿参数模型的表现优于OpenAI的DALL-E 3和Stability AI的Stable Diffusion 3-Medium等模型。尽管DALL-E 3是OpenAI在2023年发布的一款老模型,而Janus Pro目前只能分析和生成规格较小的图像(384 x 384),但其在如此紧凑的模型尺寸中依然展现了令人印象深刻的性能。
技术报告显示,在视觉生成方面,Janus-Pro通过添加7200万张高质量合成图像,使得在统一预训练阶段真实数据与合成数据的比例达到1:1,实现了更具视觉吸引力和稳定性的图像输出。在多模态理解的训练数据方面,新模型参考了DeepSeek VL2并增加了大约9000万个样本。
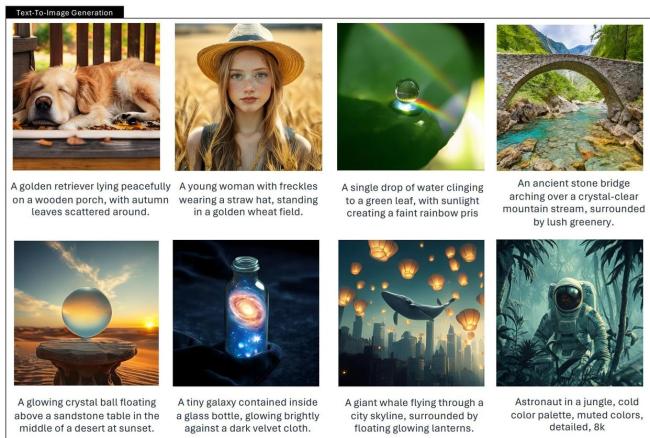
作为一个多模态模型,Janus-Pro不仅可以“文生图”,还能对图片进行描述,识别地标景点(例如杭州的西湖),识别图像中的文字,并能对图片中的知识(例如“猫和老鼠”蛋糕)进行介绍。公司在报告中展示了更多图像生成的案例。
文章来源于网络。发布者:火星财经,转载请注明出处:https://www.sengcheng.com/article/14026.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 