
中国AI初创公司深度求索(DeepSeek)在短短一个月内发布了两款大模型:DeepSeek-V3和DeepSeek-R1。这两款模型成本低廉,性能与OpenAI相当,引起了硅谷的关注,甚至引发了Meta内部的恐慌,工程师们开始连夜尝试复制DeepSeek的成果。

Scale AI创始人Alexander Wang在接受采访时提到,DeepSeek在他们的测试中表现最好,与美国最好的模型相当。他还表示,DeepSeek-V3是中国科技界带给美国的一个苦涩教训,中国以更低的成本、更快的速度和更强的实力赶超了美国。
国外媒体也对中国AI的新进展给予了高度关注,认为这些进展为硅谷敲响了警钟。在5000亿美元的“星际之门”计划公布之际,DeepSeek以极低的价格建立了一个突破性的AI模型,且未使用尖端芯片,这让人质疑巨额资本投入是否是最有效的方法。
一名Meta员工在匿名平台上透露,由于DeepSeek-V3的表现,Meta已经进入恐慌模式。DeepSeek-V3在基准测试中超越了Llama 4,而其训练预算仅为550万美元。Meta的工程师们正在争分夺秒地分析DeepSeek的技术,试图复制其成功。管理层则为GenAI研发部门的巨额投入感到焦虑,因为单个高管的薪资就超过了训练整个DeepSeek V3的成本。

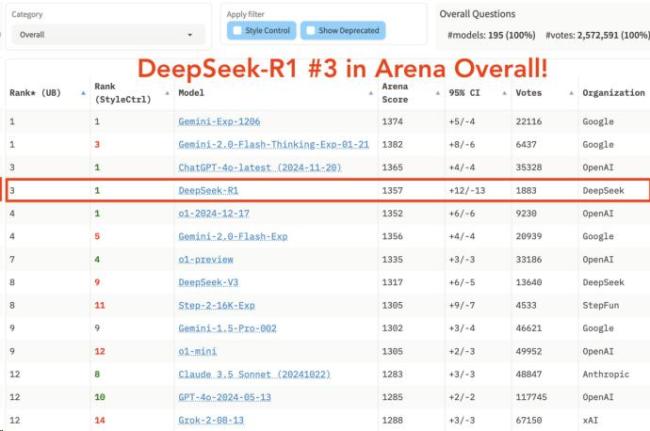
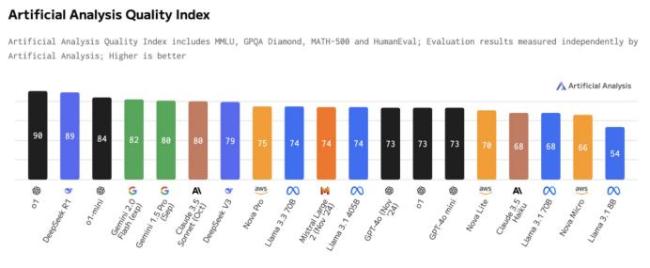
去年12月27日,DeepSeek推出开源模型DeepSeek-V3,在聊天机器人竞技场排名第七,是全球前十中性价比最高的模型。不到一个月后,DeepSeek正式开源R1推理模型,允许所有人在遵循MIT License的情况下蒸馏R1训练其他模型。1月24日,DeepSeek-R1在聊天机器人竞技场综合榜单上排名第三,与顶尖推理模型o1并列。在高难度提示词、代码和数学等技术性领域,DeepSeek-R1表现出色,排名第一。风格控制方面,DeepSeek-R1同样与o1并列第一。
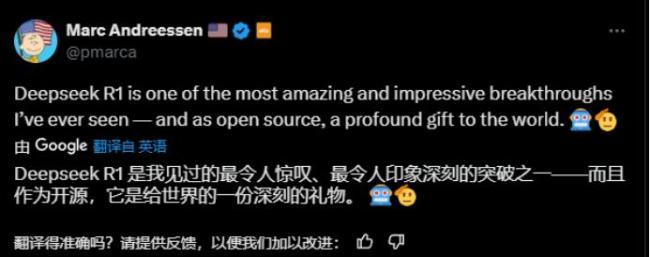
著名投资公司A16z的创始人马克·安德森称赞Deepseek-R1是他见过最令人惊叹的突破之一,而且还是开源的。A16z合伙人Anjney Midha也表示,DeepSeek-R1几乎一夜之间成为美国顶尖大学研究人员的首选模型。

对于中国AI快速发展的原因,诺奖得主、“AI教父”杰弗里·辛顿认为中国的STEM教育比美国更好,拥有更多受过良好教育的人才,这为AI的发展提供了坚实的基础。尽管美国试图通过限制来减缓中国的发展,但这只会促使中国加速发展自己的技术。

斯坦福大学和Epoch AI的研究人员发表的研究表明,到2027年,最大型的模型训练成本将超过10亿美元。然而,DeepSeek的训练成本并不昂贵,Noah’s Arc资本管理公司认为DeepSeek-V3有可能彻底改变训练和推理领域的游戏规则。一些投资者对此表示担忧,认为这种低成本的突破可能会对行业带来重大影响,甚至挑战美股芯片股的股价。
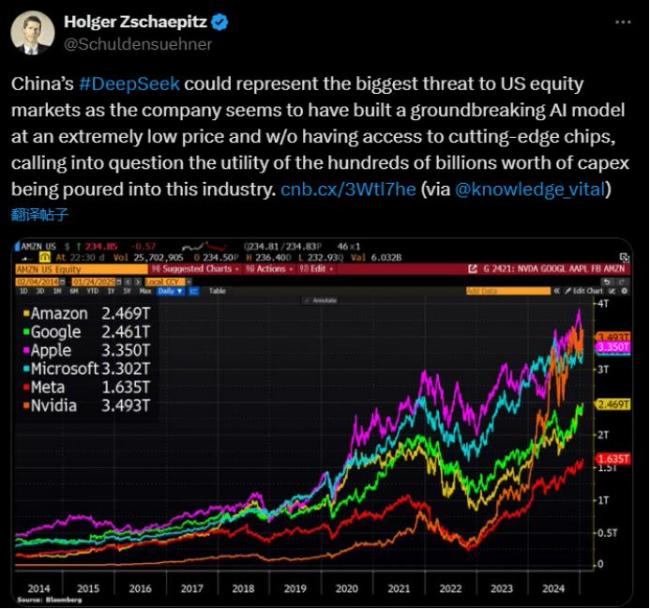
外媒纷纷报道DeepSeek的新进展,认为其为硅谷敲响了警钟。Business Insider报道称,DeepSeek-R1的开源特性可能挑战那些试图通过出售技术赚取巨额利润的公司。CNBC邀请Perplexity CEO Aravind Srinivas分析了DeepSeek引发的担忧。英国《金融时报》也报道了DeepSeek如何震惊硅谷,并探讨了资源更丰富的美国AI公司能否捍卫其技术优势。加州大学伯克利分校AI政策研究员Ritwik Gupta指出,中国的系统工程师人才库比美国大得多,他们懂得如何充分利用计算资源来更便宜地训练和运行模型。


主题测试文章,只做测试使用。发布者:火星财经,转转请注明出处:https://www.sengcheng.com/article/13624.html