
中国国产大模型Deepseek在硅谷引起了轰动。从斯坦福到麻省理工,Deepseek R1几乎一夜之间成为美国顶尖大学研究人员的首选模型。AMD宣布已将新的DeepSeek-V3模型集成到Instinct MI300X GPU上,该模型旨在与SGLang一起实现最佳性能,并针对AI推理进行了优化。
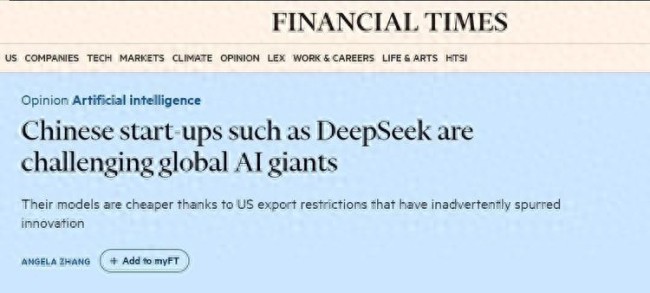

一名Meta员工发文称,由于DeepSeek的低成本高性能,他们公司的人工智能部门陷入恐慌。自中国深度求索公司发布DeepSeek-V3模型以来,在双方的性能测试中,Meta重金打造的Llama 4模型从未胜出。在美国匿名职场论坛TeamBlind上,也有Meta员工表示:“Meta生成式人工智能部门陷入恐慌。”
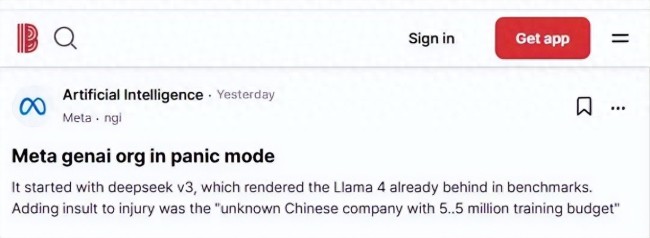
美国《商业内幕》网站报道称,Deepseek这家创新实力超群的中国人工智能初创企业发布了新的人工智能模型DeepSeek-R1,完全可以媲美OpenAI的GPT-3模型,其推理能力令美国科研人员感到震惊。CNBC上线了一篇长达40分钟的视频纪录片,报道了Deepseek的情况,认为这个事情颠覆了他们对AI的常识。报道指出,Deepseek完全由幻方资助,没有外部融资,而且是开源所有模型,在多项测试中超过了OpenAI的同类模型,使用的是低功耗的H800芯片,通过蒸馏大法仅花费了500万美元,远低于Meta公司AI部门任何一位高管的年薪。
关于人工智能发展的三大因素——算法、算力和数据,中国在算力方面一直落后,主要是因为美国限制台积电为华为代工人工智能芯片,并限制中国购买最新的英伟达显卡。美国国内的AI认知认为算力是AI的核心,发展AI就是要不断堆算力堆GPU。然而,DeepSeek-R1是在美国政府不断加大对中国人工智能领域“卡脖子”力度的背景下诞生的,它通过创新的工程设计与高效的训练方法,在有限的运算能力中实现了高性能,纯靠强化学习就达到了与GPT-3相当的水平。其训练成本极低,只用了1024张英伟达H800显卡,花费只有560万美元,而OpenAI的ChatGPT-GPT-3使用了至少一万张更为先进的英伟达H100显卡,成本大约为1亿美元。

有媒体形容,这可能是大语言模型的典范转移,今后的AI发展重点在于不依赖庞大的运算资源下创造高质量产品。Deepseek的成功证明,中国这家初创公司以极少的算力、极低的成本便能达到美国企业纯粹靠堆算力才能达到的效果。这对英伟达及其CPO技术是绝对利空。在中国禁先进AI算力卡的背景下,中国可以采用英伟达20%左右的国产算力卡来与美国竞争。这意味着,使用中国AI芯片的中国大模型完全可以不逊色于美国顶尖大模型,而且成本更低,降低了中小企业与开发者的进入门槛,增加了选择性。

硅谷巨头们也可能会加入中国的玩法与游戏规则,否则根本无法抗衡。这对行业的影响是,他们不再需要大量堆GPU,硬件方面的确定性变得不确定。高性能AI芯片的红利期可能要过去了。英伟达面临巨大挑战,或许黄仁勋也没有想到,有一天会遭遇跨界打击的命运。
主题测试文章,只做测试使用。发布者:火星财经,转转请注明出处:https://www.sengcheng.com/article/13374.html